🎙️ Local Speech-to-Text with NVIDIA Parakeet ASR (TDT 0.6B)
A fully local, GPU-accelerated speech-to-text system using NVIDIA Parakeet-TDT 0.6B, with punctuation, timestamps, and real-world audio demos.

Ever spent hours cleaning up a transcript? Inserting commas, capitalizing words, adjusting timestamps, and fixing numbers spoken as “twenty-two thousand three hundred ten” rather than “22,310”? I was tired of cloud-based speech recognition tools that compromised privacy and desktop solutions that delivered flat, unpunctuated text without timestamps.
So I tried Parakeet-TDT.
TL;DR
Most speech-to-text tools miss key elements like punctuation, timestamps, or rely on cloud APIs. This blog showcases a fully local transcription system using NVIDIA’s Parakeet-TDT 0.6B model.
✅ Auto punctuation & capitalization
✅ Word/segment-level timestamps
✅ Long audio support
✅ Tested on financial news, lyrics, and tech conversations
✅ Built using Streamlit + NeMo — runs 100% offline
🎯 The Problem: ASR That Misses the Metadata
Most ASR tools do a decent job with basic transcripts. But they fall short when real-world applications demand:
📈 Business number accuracy
🧾 Structured formatting
🔐 Local processing with privacy
🎬 Subtitle alignment
Whether you’re handling earnings calls, voice notes, or executive interviews, flat transcripts won’t cut it.
💡 The Solution: NVIDIA Parakeet-TDT 0.6B
🎥 Live Demo
Watch Parakeet transcribe business audio, lyrics, and interviews — entirely offline:
A full walkthrough of the local ASR system built with Parakeet-TDT 0.6B. Includes architecture overview and transcription demos for financial news, song lyrics, and a tech dialogue.
Note: The lyrics demo segment (Wavin’ Flag) has been muted to comply with copyright restrictions on YouTube.
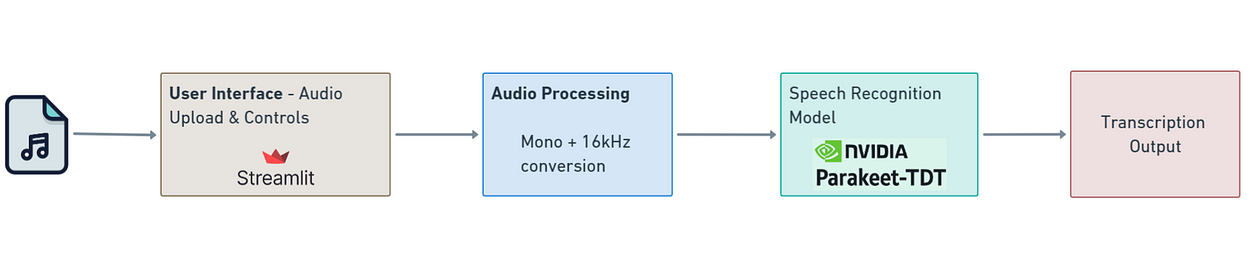
⚙️ Key Features
Auto punctuation & casing
Word and segment-level timestamps
Handles long audio (up to 24 mins per chunk)
CUDA-accelerated
Free for commercial use (CC-BY-4.0)
Fast: RTFx 3380 (~56 min of audio/sec at batch size 128)
🧠 Under the Hood: Architecture & Training
📐 Architecture
FastConformer encoder + TDT decoder
600M parameters
Trained on over 120K hours
🧪 Training Overview
Pretrained with wav2vec on LibriLight
Fine-tuned on 500 hours of clean speech
Final training on YouTube-like public datasets
Trained using NVIDIA NeMo on 64× A100 GPUs
💻 Setup: Run It Locally (Windows)
The code, requirements, and sample audio files are available on GitHub:
🔗 GitHub — SridharSampath/parakeet-asr-demo
1. Create Conda Environment
create -n parakeet-asr python=3.10 -y
conda activate parakeet-asr
2. Install Dependencies
pip install -r requirements.txt
Includes NeMo, PyTorch, Streamlit, and audio libraries.
3. Install FFmpeg
choco install ffmpeg
🧠 Code Walkthrough
🔌 Load the Model
model = ASRModel.from_pretrained("nvidia/parakeet-tdt-0.6b-v2")
model = model.to("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
model = model.to(torch.bfloat16)
🎧 Audio Preprocessing
audio = AudioSegment.from_file(audio_path)
audio = audio.set_frame_rate(16000).set_channels(1)
audio.export("processed.wav", format="wav")
📝 Transcription
output = model.transcribe([processed_path], timestamps=True)
for seg in output[0].timestamp["segment"]:
print(f"{seg['start']}s - {seg['end']}s: {seg['segment']}")
Streamlit handles exporting to .csv, .srt, and .txt.
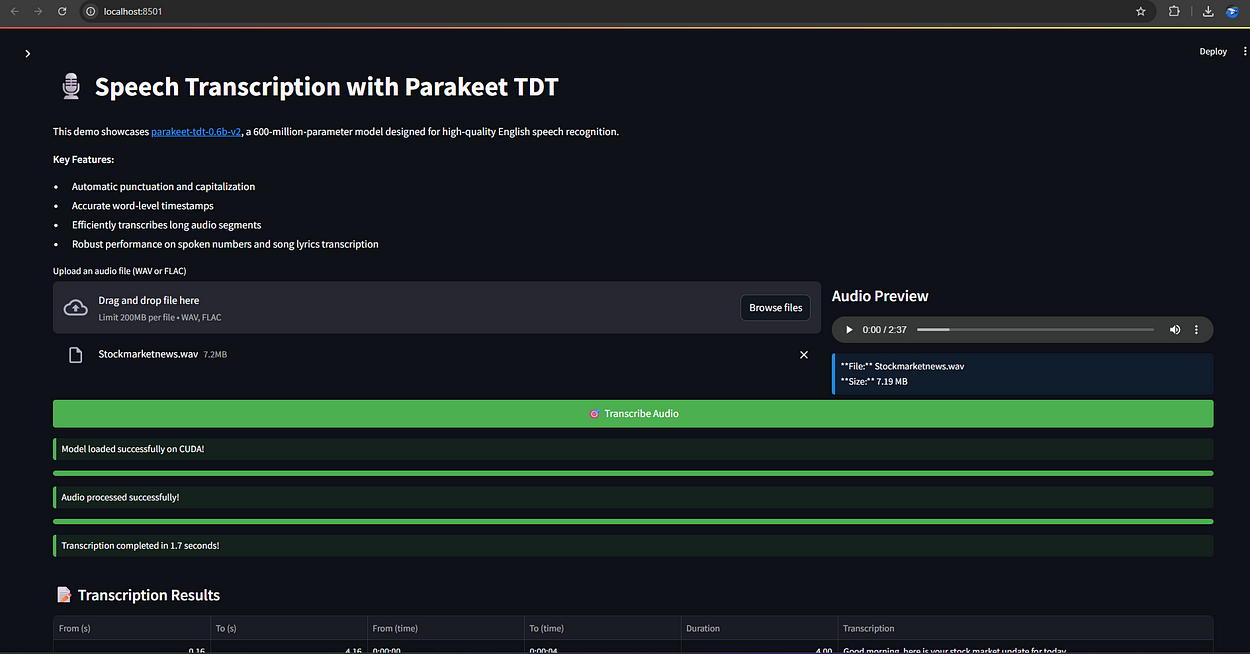
🖥️ Application Interface — Local ASR in Action
System runs fully offline, loads the 600M model in seconds, and transcribes a 2:37 clip in under 2 seconds on CUDA.
🧪 Real-World Transcription Tests
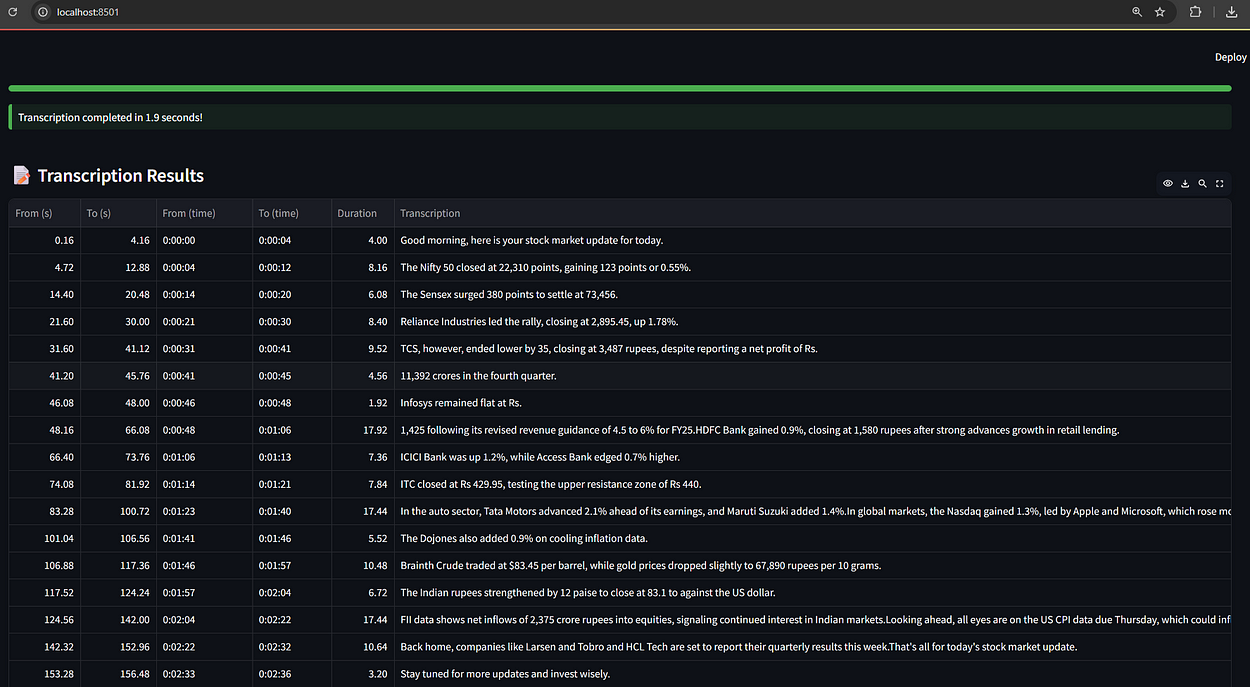
1. Stock Market News (2:30 mins)
🎧 File: Stockmarketnews.wav
Simulates a financial update with spoken numbers, companies, and currencies.
Transcription wins:
Phrases like “The Nifty 50 closed at 22,310 points”
Correct formatting for “₹3,487” and percentage figures
Accurate punctuation and clarity
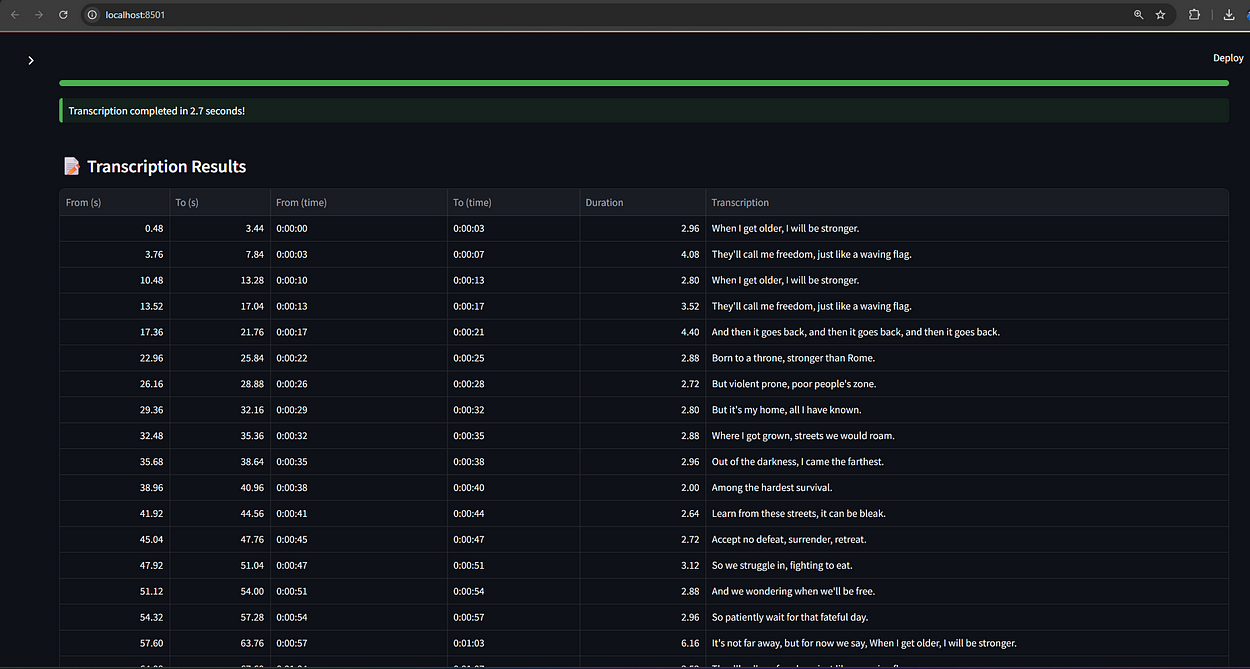
2. Song Lyrics — Wavin’ Flag (3:40 mins)
🎧 File: Wavin-Flag-song.wav
Focuses on lyric structure and repetition.
Transcription wins:
Captures phrasing: “When I get older, I will be stronger…”
Punctuation preserves rhythm
Line breaks and structure detected
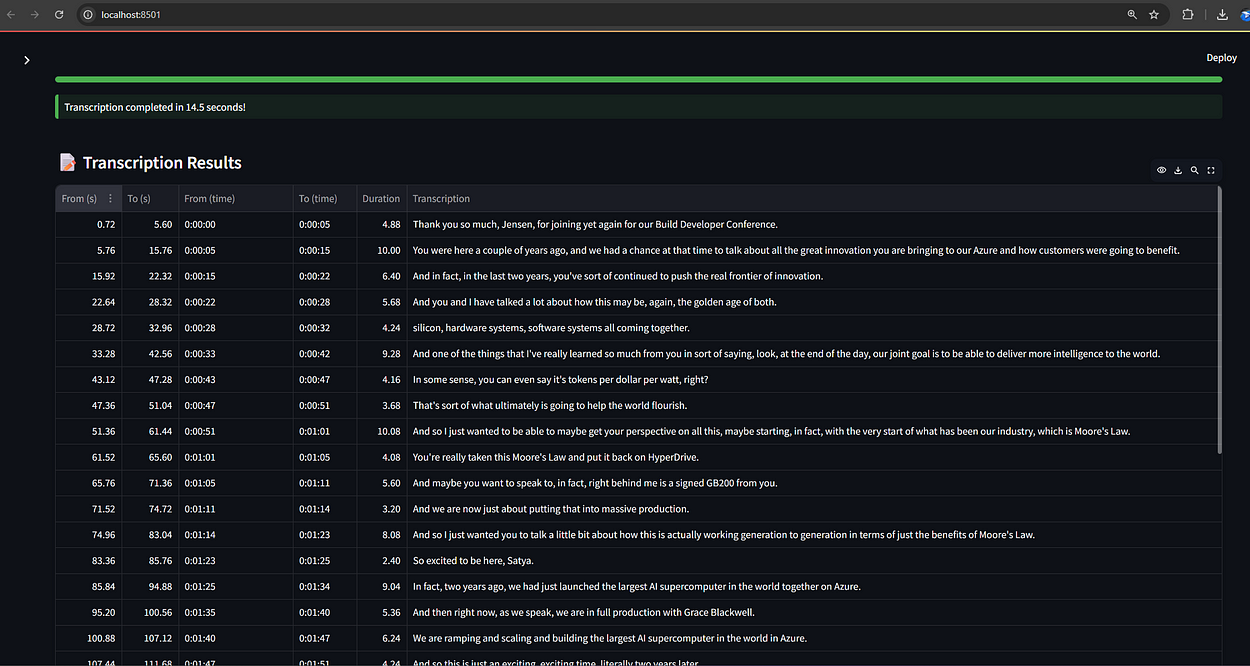
3. Tech Dialogue — Satya x Jensen (5:00 mins)
🎧 File: JensenHuang-SatyaNadella-Conference-talk.wav
First 5 minutes of a Build Conference chat on AI.
Transcription wins:
Captures phrases like “tokens per dollar per watt”
Maintains sentence integrity and structure
Handles longer, multi-speaker content
🧾 Sample Audio Files
JensenHuang-SatyaNadella-Conference-talk.wavStockmarketnews.wavWavin-Flag-song.wav
Available in the GitHub repo
📊 Parakeet vs Whisper (Medium)
| Feature | Parakeet-TDT 0.6B | Whisper Medium |
| Params | 600M | 769M |
| WER (test-clean) | 2.5% | 3.6% |
| WER (test-other) | 6.2% | 7.8% |
| RTFx (batch) | 3386 | ~300 |
| Word-level timestamps | Yes | No |
| Commercial license | CC-BY-4.0 | MIT |
| Financial number accuracy | Excellent | Good |
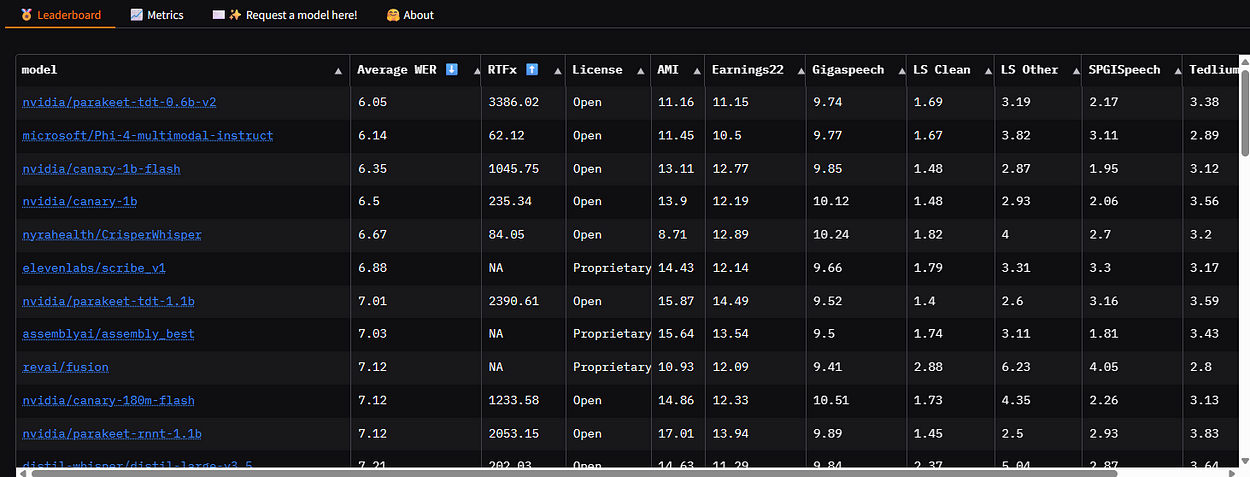
🏆 Benchmark Leadership
Parakeet ranks #1 on Hugging Face Open ASR Leaderboard (as of May 2025):
WER: 6.05% (best open model)
RTFx: 3386
License: CC-BY-4.0
⚠️ Limitations
English-only
Requires GPU (CUDA) for optimal performance
No built-in speaker diarization
🧠 Final Thoughts
Parakeet-TDT 0.6B offers a strong open-source alternative to Whisper for English transcription — especially when speed, timestamps, and offline processing are critical.
Perfect for:
Executive interviews
Financial transcription
Subtitles & media apps
Research projects
⚙️ Test Environment
GPU: NVIDIA RTX 3050 Laptop GPU
CUDA: 11.8
OS: Windows 11
Frameworks: NeMo + PyTorch
🔗 Resources
🙌 Let’s Connect
If you're exploring ASR, real-time transcription, or multimodal RAG — I'd love to connect:



